What is a buffer?
In node.js a buffer is a container for raw bytes. A byte just means eight bits, and a bit is just a 0 or a 1. So a byte might look like 10101010 or
- At the lowest level, all data in your computer is represented by bits. And even though in node.js you work with things like numbers, strings, booleans, these are all abstractions that were built on 0s and 1s (i.e. bits!). This means that whenever your program wants to communicate outside of node.js you can’t rely on those data types existing anymore, so instead this communication happens in bits. That’s why if you’ve ever tried to read a file or worked with sockets, you probably got back a buffer.
What does a buffer look like?
Here’s an example of what a buffer might look like if you console.log it in the terminal.
<Buffer 02 04 06 08 0a 0c 0e 10>
You can see that a buffer has an object type of Buffer. Then you see some numbers grouped in pairs. Because there are 8 pairs, you know that this buffer has a size of 8. What do these numbers represent?
Well, since a buffer is a container for bytes, you might have guessed that these numbers are bytes. But if a byte is a group of 8 bits, how can two numbers represent a byte? Shouldn’t it be 8 numbers? And why do some of the numbers have letters?
Number systems
The short answer is that in order to save space and be more readable, the implementers of node.js have chosen to display a hexadecimal numbers instead of a binary numbers. What does that mean?
When we ordinarily think of number we think of each digit as ranging from 0-9. This is what’s called a decimal number system, or a base-10 number system. But it’s possible to have other number systems, such as binary which is a base-2 number system. Each digit only ranges from 0-1. Hexadecimal is still another number system, this time each digit ranges from 0-15. Perhaps the easiest way to understand this concept is by looking at a conversion chart:
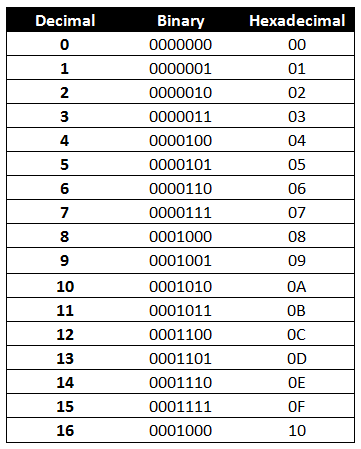
It just so happens that any 8 digit binary number can be represented by a 2 digit hexadecimal number. That’s why we see two digit for each byte in the buffer.
Encoding
Strings
There’s one last thing we need to understand about buffers and bytes before looking at how to use them — encoding. Just looking at a bunch of bytes you can’t actually tell what those bytes are meant to represent; you also have to know the encoding. For example, let’s say we have this buffer:
const Buffer = require('buffer').Buffer;
const buf = Buffer.from([0x68, 0x65, 0x6c, 0x6c, 0x6f, 0x20, 0x77, 0x6f, 0x72,
0x6c, 0x64]);
console.log(buf);
// outputs <Buffer 68 65 6c 6c 6f 20 77 6f 72 6c 64>If we want to read those bytes as a string, we need to know what characters those bytes map to. That mapping is the encoding. Different encodings will translate to different strings. Here you can see the output of reading the buffer above as a string using the ‘utf16le’ and ‘utf8’ encodings.
const Buffer = require('buffer').Buffer;
const buf = Buffer.from([0x68, 0x65, 0x6c, 0x6c, 0x6f, 0x20, 0x77, 0x6f, 0x72,
0x6c, 0x64]);
console.log(buf);
// outputs <Buffer 68 65 6c 6c 6f 20 77 6f 72 6c 64>
console.log(buf.toString('utf16le'));
// outputs '敨汬潷汲'
console.log(buf.toString('utf8'));
// outputs 'hello world'Encodings work in “both directions”. That is, you can convert from a buffer to
a string and from a string to a buffer. We already saw that converting to a
string can be done with the toString method. To get a buffer from a string you
can use the Buffer.from method like this:
const Buffer = require('buffer').Buffer;
console.log(Buffer.from('hello world', 'utf8'));
// outputs <Buffer 68 65 6c 6c 6f 20 77 6f 72 6c 64>In both cases the default encoding is ‘utf8’ so you don’t have to pass an encoding, but I think it’s better to be explicit.
Numbers
You might be surprised to hear that numbers have an encoding too. But with numbers the encoding is determined by 3 different properties: the bit-length of the number, the type of number, whether or not its signed, and whether it is big- or small-endian.
-
Bitlength is how many bits are used to represent the number. For example if a number has a bitlength of 8, then it must use 8 bits. If some of the bits are unused then they’re just set to 0. For example 4 as an 8 bit number could be 00000100, i.e. 100 with zero-padding on the left side.
-
In node, a number can be either an integer, a float, or a double. Floats and doubles are both number that use a decimal point (e.g. 1.9395) but a float has a bitlength of 32, while a double has a bitlength of 64 (double the bitlength of a float).
-
A signed number is one that can be either negative or positive. Unsigned numbers are always assumed to be positive. You can check out how signed numbers are represented here. Floats and doubles are assumed to be signed.
-
Endianness means whether the number should be read from left to right or right to left. Normally we think of numbers as being big-endian where the digits on the left are “bigger” than the digits on the right. For little-endian numbers its the other way around, so 0001 is actually what we normally think of as 1000, and 1000 is what we normally think of as 0001. Actually, this is not quite true, as endianness is a byte-level property. Each individual byte of a number is always read left to right, but endianness determines the ordering of the bytes in relation to each other. So
<Buffer 01 02>and<Buffer 02 01>could be the same number with different endianness.
Working with buffers
Conceptually buffers are quite similar to arrays. They use bracket indexing and
assignment just like arrays, and they have a length property as well as a concat
and a slice method that works in basically the same way as arrays. However
unlike javascript arrays, javascript buffers have a fixed length.
You can find the official documentation here.
Creating buffers
There are lot of ways to create a buffer but the simplest is probably just using
the alloc method. If you know you’re going to fill up the buffer immediately
then you can use allocUnsafe which is more efficient but doesn’t clear out
random unused bytes from the buffer.
Or you can use the from method, where you’ll most commonly be passing in an
array of numbers, a string, or another buffer. If you pass a string, you’ll
want to also pass an encoding (or use the default ‘utf8’).
Note that new Buffer is considered deprecated, so you’ll want to use the
alloc, allocUnsafe, or from methods instead.
Using buffers
Strings
If you want to read or write a string to a buffer, then you can use the toString
or from methods respectively. Remember you should specify the encoding or you
will use utf-8 by default. I prefer to pass the encoding explicitly even if I’m
using utf-8.
const Buffer = require('buffer').Buffer;
const buf = Buffer.from('hello world', 'utf8');
console.log(buf.toString('utf8'));
// outputs 'hello world'Numbers
If you want to read a number out of the buffer, there is a set of built in methods that specify what bitlength, encoding, and endianness you’re dealing with. The method names follow the following convention:
- Either ‘read’ or ‘write’ to indicate the type of operation.
- Followed by either ‘Float’, ‘Double’, ‘Int’, or ‘UInt’ (unsigned int).
- Followed by the bitlength. This isn’t used by floats or doubles since they have an assumed bitlength of 32 and 64 respectively.
- Followed by ‘BE’ or ‘LE’, big-endian and little-endian respectively. This isn’t used by 8 bit integers because endianness is a byte-level property. You can’t order a single byte.
const Buffer = require('buffer').Buffer;
// create an empty buffer with length of 4 bytes.
const buf = Buffer.alloc(4);
// write the unsigned 32-bit, big-endian number 123 into the buffer starting
// at index 0 of the buffer.
buf.writeUInt32BE(123, 0);
// read the number starting at index 0
console.log(buf.readUInt32BE(0));
// outputs: 123Copy
The above methods will cover almost everything you want to do with buffers, but
there are some other methods that are occasionally useful. I find copy
especially useful when you already have a buffer and you want to write its
content into another buffer. For example:
const Buffer = require('buffer').Buffer;
// create an empty buffer with length of 11 bytes.
const buf = Buffer.alloc(11);
// create two buffers, one that contains 'hello ', the other 'world'.
const word1 = Buffer.from('hello ', 'utf8');
const word2 = Buffer.from('world', 'utf8');
// copy the word buffers into `buf` at index 0 and 6 respectively.
word1.copy(buf, 0);
word2.copy(buf, 6);
console.log(buf.toString('utf8'));
// outputs 'hello world'